
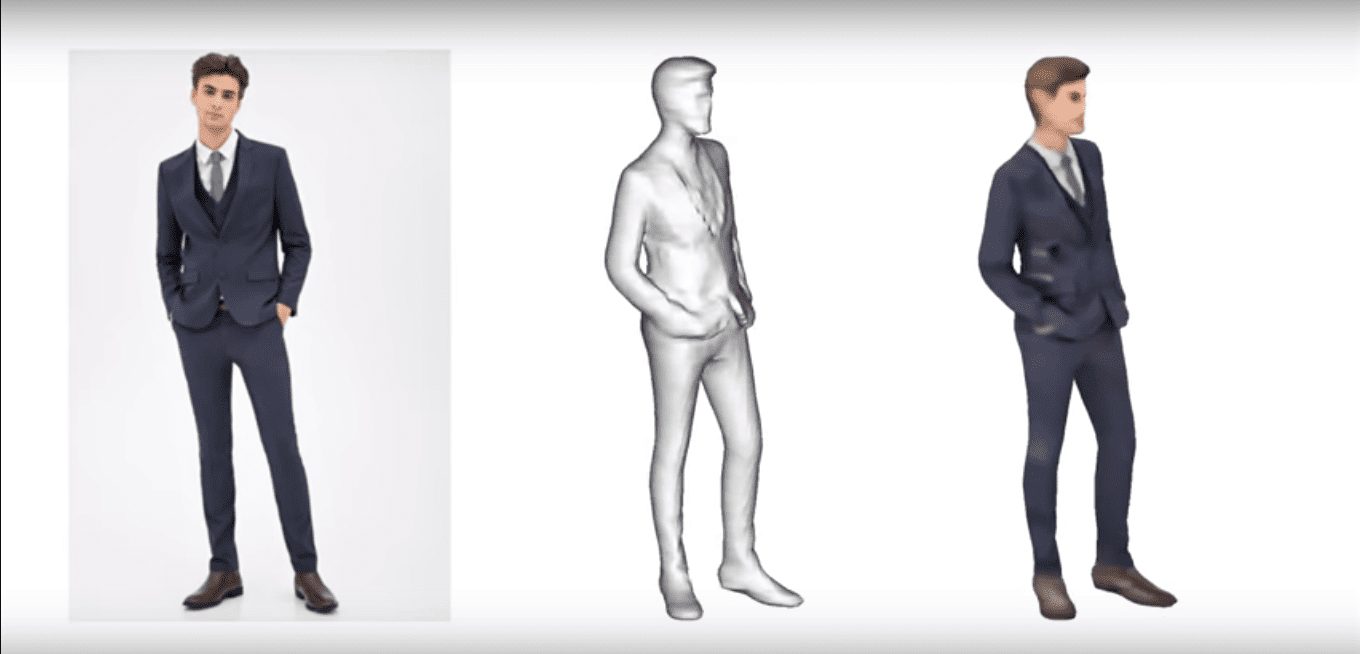
Американские и японские разработчики научили нейросеть создавать 3D-модель человека по одной или нескольким фотографиям. Особенность алгоритма заключается в том, что он достаточно качественно воссоздает даже вид со спины, которая не видна на исходном снимке, рассказывают авторы статьи, которая будет представлена на конференции ICCV 2019.
Создание 3D-модели по 2D-снимку, например, обычной фотографии, связано с фундаментальной проблемой — одному и тому же плоскому снимку могут соответствовать объемные предметы разной формы. Тем не менее, если задача заключается в восстановлении формы объектов конкретного типа, то она значительно упрощается, потому что, к примеру, люди имеют похожую фигуру, хотя и различающуюся в некоторых пропорциях.
Еще одна проблема таких алгоритмов заключается в том, что фотография несет в себе данные лишь с одного ракурса. Кроме того, современные алгоритмы воссоздания объемной модели зачастую восстанавливают лишь ее саму, без учета цвета на снимке.
Разработчики под руководством Хао Ли (Hao Li) из Университета Южной Калифорнии научили нейросеть достаточно точно воссоздавать цветную модель тела человека со всех сторон, на основе одной или нескольких фотографий.
Алгоритм состоит из двух последовательных сверточных нейросетей. Первая из них получает исходный снимок и начинает для каждой точки трехмерного куба рассчитывать, что в ней находится: часть тела человека или пустое пространство. Затем эти данные с помощью алгоритма, известного как «Шагающие кубики», преобразуются в полигональную 3D-модель.
После того, как полигональная модель создана, ее начинает обрабатывать вторая нейросеть, которая устроена таким же образом, но выдает не статус точек в пространстве, а их цвет. Таким образом, в результаты обработки снимка алгоритм создает полноценную 3D-модель, каждая точка поверхности которой имеет цвет, причем даже если этой точки не было видно на исходном снимке. Для улучшения результатов алгоритм также поддерживает ввод нескольких снимков с разных ракурсов.
Разработчики обучали нейросеть на собственном датасете, созданном из 491 модели из базы RenderPeople — это набор высококачественных 3D-моделей людей, полученных с помощью фотограмметрических сканеров. На основе этих моделей они создали почти 160 тысяч снимков для обучения алгоритма.
На опубликованном авторами ролике можно видеть, что алгоритм достаточно качественно воссоздает всю модель, в том числе и со спины, которая не видна на исходном снимке. Кроме того, на ролике продемонстрировано, что даже наличие трех кадров вместо одного значительно повышает качество итоговой модели. Наконец, авторы показали, что во многих аспектах алгоритм справляется с воссозданием 3D-модели лучше, чем аналогичные алгоритмы других разработчиков.